Custom Index
Data Model
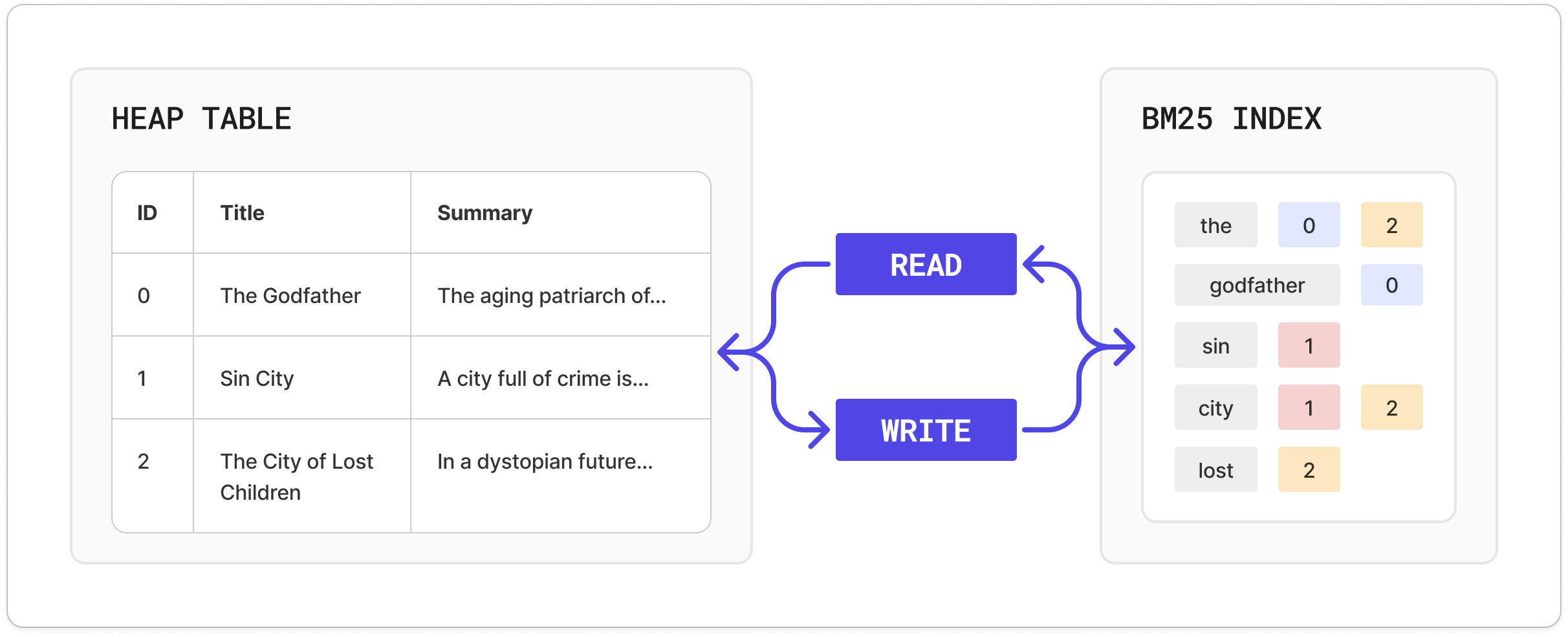
Inverted Index
An inverted index is a structure that maps each term (i.e., tokenized word) to a list of documents that contain that term (called a “postings list”) along with metadata like term frequency and document frequency. This structure allows ParadeDB to efficiently retrieve all documents matching a particular search term or phrase without scanning the entire table.Columnar Index
Alongside the inverted index, ParadeDB also maintains a structure that stores fields in a column-oriented format. Columnar formats are standard for analytical (i.e. OLAP) databases because they store values contiguously and enable efficient scans over large datasets compared to Postgres’ row-oriented layout. All text fields which use the literal or literal normalized tokenizer, or are non-text, are stored in the columnstore. In Tantivy these structures are referred to as fast fields, but they are largely transparent in ParadeDB.LSM Tree
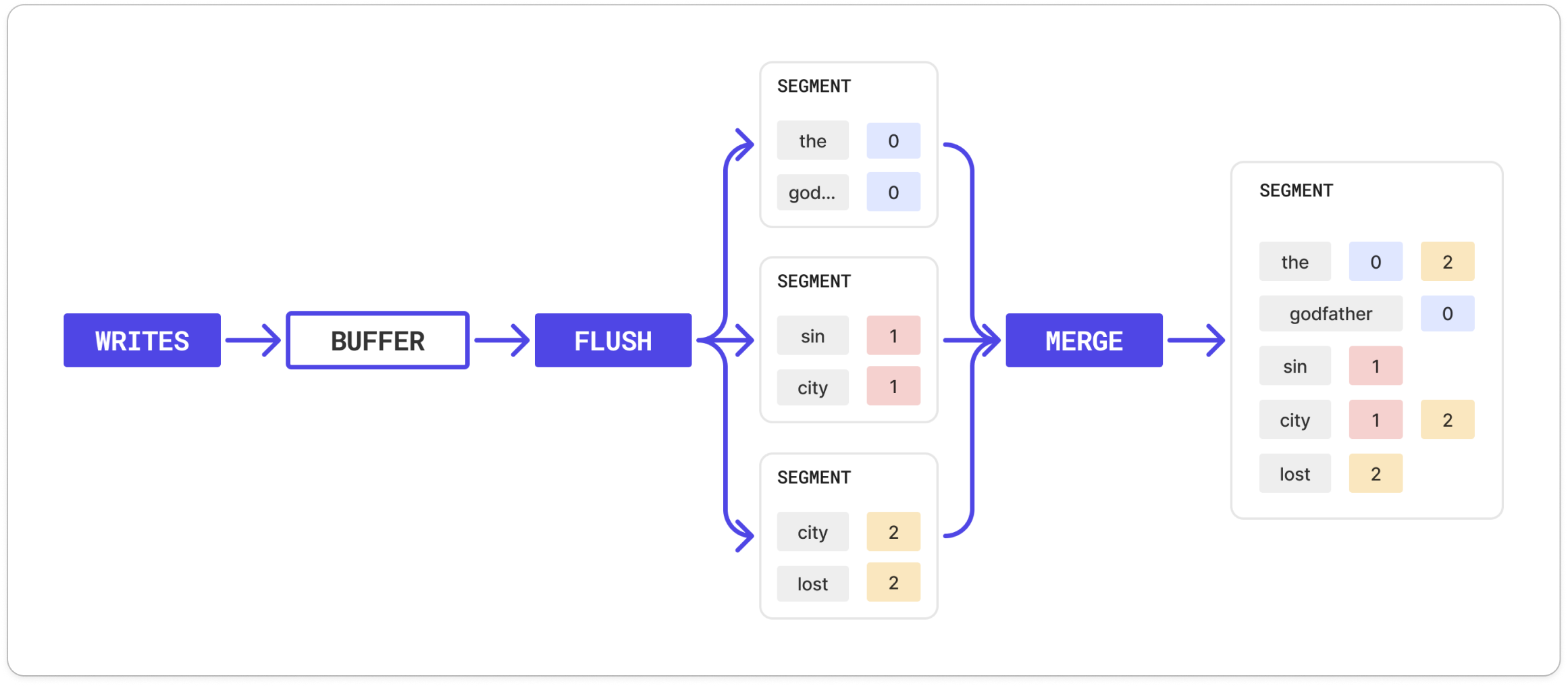
To support real-time updates, the BM25 index uses a Log-Structured Merge (LSM) tree. An LSM tree is a write-optimized data structure commonly used in systems like RocksDB and Cassandra. The core idea behind an LSM tree is to turn random writes into sequential ones. Incoming writes are first stored in an in-memory buffer, which is fast to update. Once the buffer fills up or the current statement finishes, it is flushed to disk as an immutable “segment” file. These segment files are organized by size into layers or levels. Newer data is written to the topmost layer. Over time, data is gradually pushed down into lower levels through a process called merging or compaction, where data from smaller segments is merged, deduplicated, and rewritten into larger segments. In ParadeDB, everyINSERT/UPDATE/COPY statement creates a new segment. Each segment has its own inverted index and columnar index, which means that the BM25 index
is actually a collection of many inverted/columnar indexes, each of which allows for very dense intersection queries to rapidly filter matches.
Query Execution
Custom Operators
ParadeDB introduces several new text search operators to Postgres. For example,||| is used for match disjunction queries, whereas ###
is for phrase queries.
Custom Scan
Whenever a ParadeDB operator is present in a query, ParadeDB will execute the query using a custom scan. Custom scans are execution nodes set aside by Postgres that allow extensions to run custom logic during a query. They are more powerful and versatile than typical Postgres index scans because they allow the extension to “take over” large parts of the query, including aggregates,WHERE, and even GROUP BY clauses.
From a performance perspective, custom scans significantly speed up queries by pushing down filters, aggregates, and other operations directly into the index, rather than applying them afterward in separate phases.
To understand what kind of scan is used, run EXPLAIN:
EXPLAIN shows a custom scan (or, in rare cases, a BM25 index scan), then that part of query is going through ParadeDB. Otherwise, the query passes through standard Postgres.
Parallelization
For queries that need to read large amounts of data like Top K or aggregate queries, the custom scan automatically spawns additional workers to execute the query in parallel. To see if a query was parallelized, runEXPLAIN ANALYZE:
Parallelization also depends on the number of available
workers.
Design Philosophy
- Keep it Boring. Use robust extension points in Postgres vs. hacking around the internals. Adopt battle-tested tools, like industry standard file formats and query engine libraries, instead of cutting-edge but less-proven alternatives.
- Behave Exactly Like Postgres. This extends from user-facing aspects, like the SQL query syntax and ORM compatibility, all the way down to low-level integrations with Postgres’ storage system and query planner.
- Works Out of the Box. Users should be able to get satisfying search results and performance with minimal tuning or configuration.
Dependencies
The three main dependencies ofpg_search are:
pgrx— the library for writing Postgres extensions in Rust- Tantivy — a Rust-based full-text search library inspired by Lucene
- Apache DataFusion — an extensible query execution framework for OLAP processing